Abstract
Accurately recovering the full 9-DoF pose of unseen instances within specific categories from a single RGB image remains a core challenge for robotics and automation.
Most existing solutions still lean on pseudo-depth, CAD models, or multi-stage cascades that separate 2D detection from pose estimation.
Motivated by the need for a simpler, RGB-only alternative that learns directly at the category level, we revisit a longstanding question: Can object detection and 9-DoF pose estimation be unified with high performance, without any additional data?
We show that they can be achieved with our YOPO, a single-stage, query-based framework that treats category-level 9-DoF estimation as a natural extension of 2D detection.
YOPO augments a transformer detector with a lightweight pose head, a bounding-box–conditioned translation module, and a 6D–aware Hungarian matching cost.
The model is trained end-to-end only with RGB images and pose labels.
Despite its minimalist design, YOPO sets a new SOTA on three benchmarks. On REAL275 dataset, it achieves 79.6% IoU$_{50}$ and 54.1% under the $10^\circ 10\,\mathrm{cm}$ metric, surpassing all prior RGB-only methods and closing much of the gap to RGB-D systems.
Code and pretrained models will be released.
Introduction
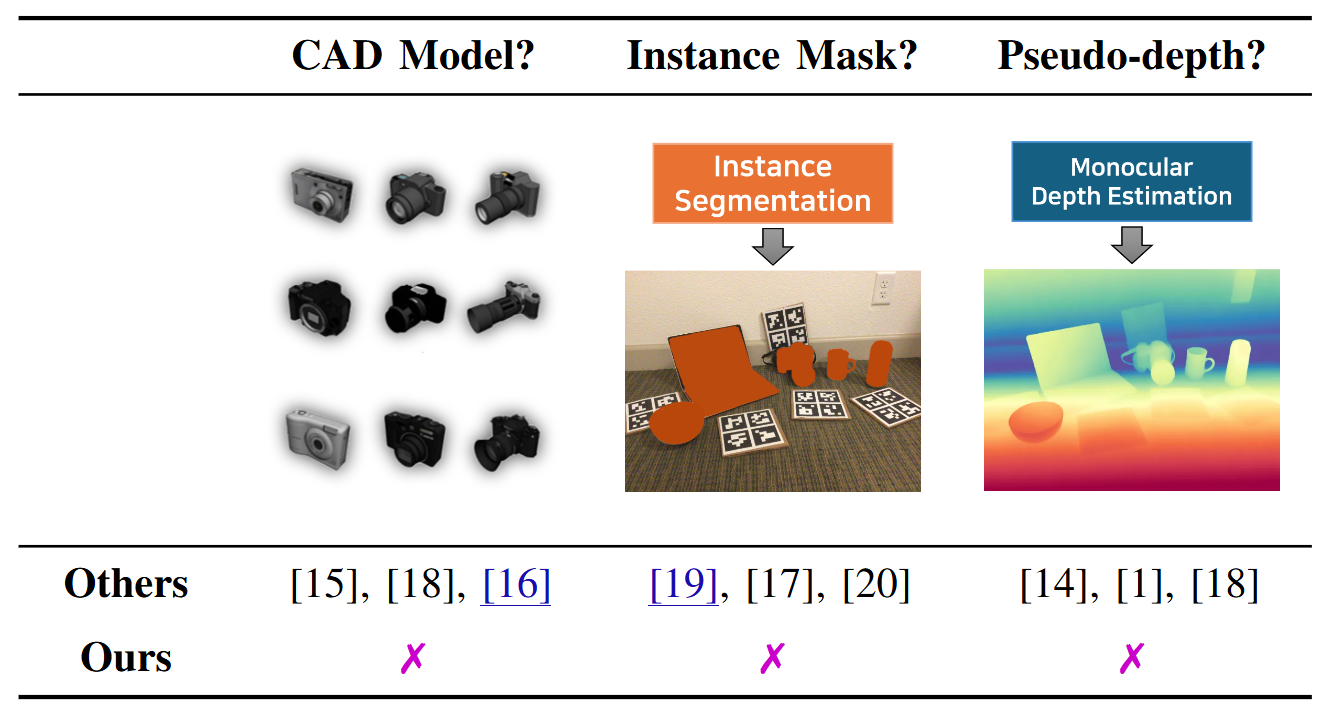
Estimating an object’s 6‑D (or, for unknown scale, 9‑D) pose from a single RGB frame is essential for robotic grasping, AR, and autonomous navigation. Most prior category‑level methods rely on extra geometric cues—CAD models, instance masks, or pseudo‑depth—plus two‑stage pipelines that first detect and then crop each object.
We asks: Can we remove all that baggage?
Objective
Develop a single‑stage, RGB‑only model that:
- Detects every object in the scene,
- Predicts its full 9‑D pose (rotation R, translation t, scale s),
- Trains and infers without CAD, masks, or depth.
Key Ideas
- Query‑based DETR backbone – inherits DINO’s two‑stage refinement to get strong 2‑D detections.
- Parallel pose head – four MLP branches regress center‑offset, depth, rotation (6‑D rep) and scale.
- Box‑conditioned translation – concatenates the 2‑D bounding box to the query so depth & offset learn geometric context.
- 3‑D‑aware Hungarian matching – assigns predictions with a cost that mixes classification, IoU, translation & rotation.
- Minimal supervision – 2‑D boxes are auto‑derived by projecting 3‑D cuboids; no extra labels required.
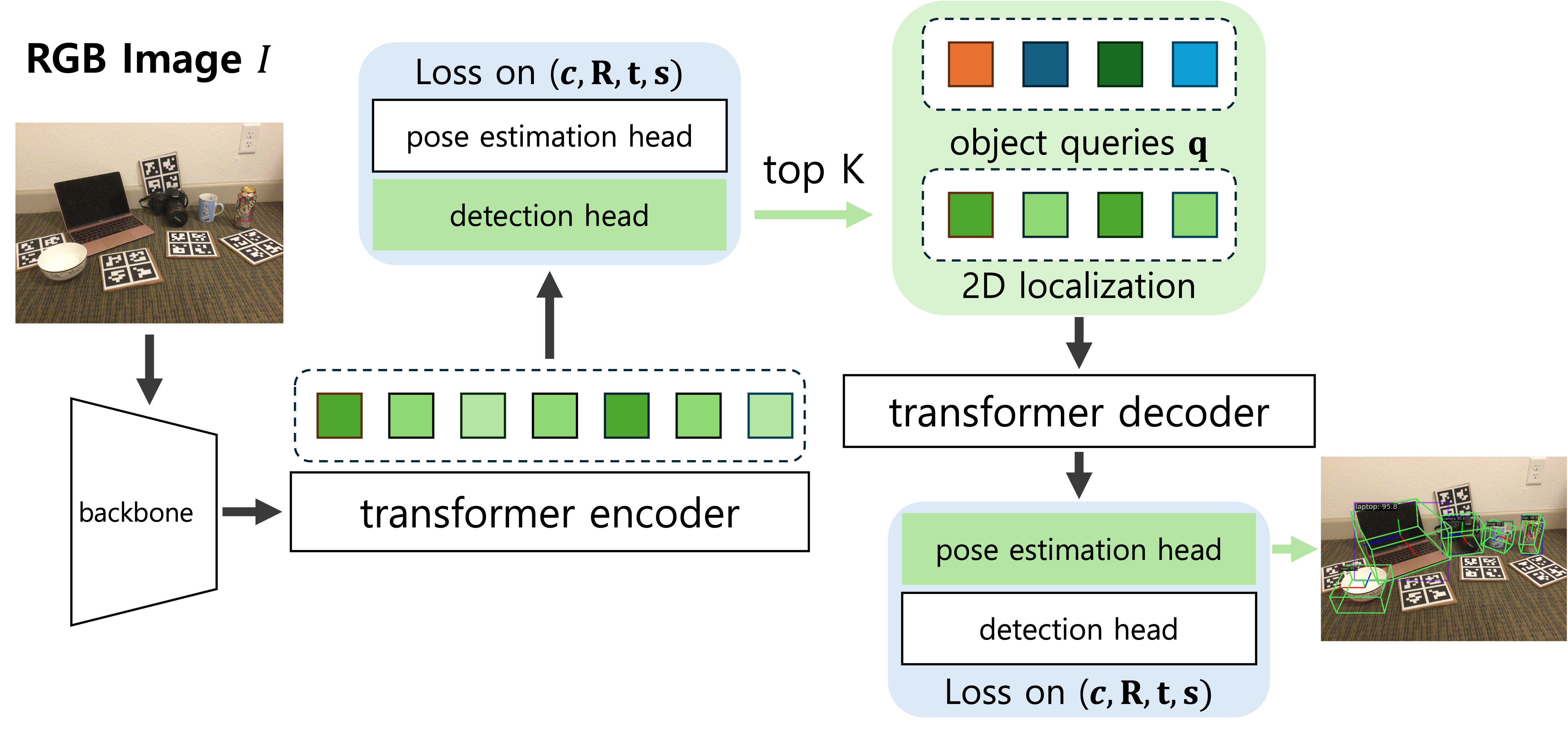
Table. Comparison of methods on additional data requirements / model pipeline
| Method | CAD Model? | Seg. Mask? | Pseudo-depth? | End-to-end? |
|---|---|---|---|---|
| Synthesis (ECCV ‘20) | ✓ | ✓ | ✗ | ✗ |
| MSOS (RA-L ‘21) | ✓ | ✓ | ✗ | ✗ |
| CenterSnap (ICRA ‘22) | ✓ | ✗ | ✗ | ✓ |
| OLD-Net (ECCV ‘22) | ✓ | ✗ | ✓ | ✗ |
| FAP-Net (ICRA ‘24) | ✓ | ✓ | ✓ | ✗ |
| DMSR (ICRA ‘24) | ✓ | ✓ | ✓ | ✗ |
| LaPose (ECCV ‘24) | ✓ | ✓ | ✗ | ✗ |
| MonoDiff9D (ICRA ‘25) | ✗ | ✓ | ✓ | ✗ |
| DA-Pose (RA-L ‘25) | ✗ | ✓ | ✓ | ✗ |
| GIVEPose (CVPR ‘25) | ✓ | ✓ | ✗ | ✗ |
| YOPO (Ours) | ✗ | ✗ | ✗ | ✓ |
YOPO is the only approach in this list that dispenses with all external cues.
Significance
- Performance. On REAL275, YOPO‑Swin‑L tops RGB baselines with 79.6% IoU50 and 54.1% under the 10°/10cm metric.
- Simplicity. Training uses just images + 9‑D labels—no costly CAD collections or instance segmentation.
- Scalability. The same architecture generalises across CAMERA25 (synthetic), REAL275 (real) and HouseCat6D (10 categories).
- Speed. One forward pass ≈ real‑time (21.3 FPS @ A6000, YOPO R50) inference suitable for robotic manipulation loops.
Experiments
Table. Comparison on the REAL275 dataset. All methods use only RGB input.
| Method | IoU50 | IoU75 | 10 cm | 10° | 10°/10 cm |
|---|---|---|---|---|---|
| Synthesis (ECCV ‘20) | - | - | 34.0 | 14.2 | 4.8 |
| MSOS (RA-L ‘21) | 23.4 | 3.0 | 39.5 | 29.2 | 9.6 |
| CenterSnap-RGB (ICRA ‘22) | 31.5 | - | - | - | 30.1 |
| OLD-Net (ECCV ‘22) | 25.4 | 1.9 | 38.9 | 37.0 | 9.8 |
| FAP-Net (ICRA ‘24) | 36.8 | 5.2 | 49.7 | 49.6 | 24.5 |
| DMSR (ICRA ‘24) | 28.3 | 6.1 | 37.3 | 59.5 | 23.6 |
| LaPose (ECCV ‘24) | 17.5 | 2.6 | 44.4 | - | 30.5 |
| MonoDiff9D (ICRA ‘25) | 31.5 | 6.3 | 41.0 | 56.3 | 25.7 |
| DA-Pose (RA-L ‘25) | 28.1 | 3.6 | 45.8 | 27.5 | 13.4 |
| GIVEPose (CVPR ‘25) | 20.1 | - | 45.9 | - | 34.2 |
| YOPO R50 (Ours) | 67.1 | 16.6 | 75.6 | 54.0 | 40.7 |
| YOPO Swin-L (Ours) | 71.6 | 16.4 | 77.8 | 67.6 | 52.8 |
| YOPO* Swin-L (Ours) | 79.6 | 19.6 | 84.4 | 66.0 | 54.1 |
Sample Results on REAL275 test Scenes
Citation
@inproceedings{lee2026yopo,
title = {You Only Pose Once: A Minimalist’s Detection Transformer for Monocular RGB Category-level 9D Multi-Object Pose Estimation},
author = {Lee, Hakjin and Seo, Junghoon and Sim, Jaehoon},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2026}
}